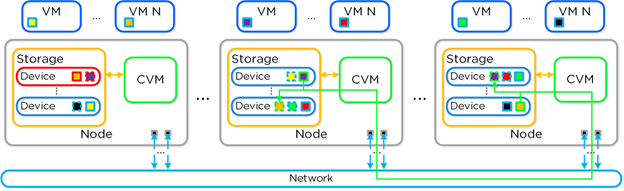
Failure = I/O’s redirected to other CVM’s in cluster
VM impact:
HA Event: NO
Failed I/O: NO
Latency: Potentially higher given I/O’s are over network (not local)
ESXi/Hyper-V handle via CVM Autopathing = leverages HA.py (happy) where routes are modified to forward traffic from internal address (192.168.5.2) to external IP of another CVM.
Keeps datastore intact
Once local CVM is back online, route is removed and local CVM takes back I/O
KVM = iSCSI multipathing leveraged
Primary path = local CVM, other two paths = remote CVM
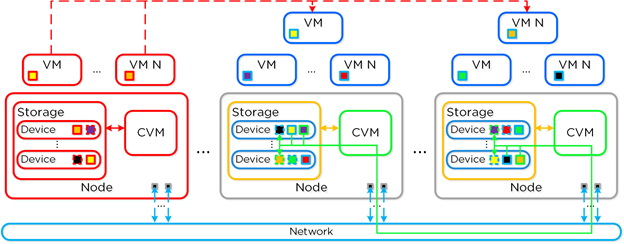
Node
Failure
VM impact:
HA Event: Yes
Failed I/O: NO
Latency: NO
VM HA event will occur, restarting VMs on other nodes
Curator will find data previously hosted on node and replicate
In event node is down for prolonged period of time, downed CVM will be removed from metadata ring.