Demonstrate how to install and configure synchronous replication for multiple hypervisors
Synchronous Replication is a feature where data is synchronously replicated between two sites in metro availability configuration. In an event of a disaster on any one site, real-time data is available on the other site.
The protection domain can be configured for metro availability or for synchronous replication depending on the following:

- Metro availability: The hypervisor is ESXi and the metro availability requirements for a single vSphere cluster across the sites and vSphere HA are satisfied.
- Synchronous replication: The hypervisor is either ESXi (not setup for metro availability) or Hyper-V.
- Neither option is currently available for AHV.
Prerequisites
- DRS rules set as fully automated to ensure VM-to-Host affinity rules on Primary site
- <=5ms RTT latency
- Ultimate license
- All VM’s in the protection domain should be on the Primary site
- Storage containers should have the SAME NAME on both clusters
Configure Remote Sites for Metro Availability
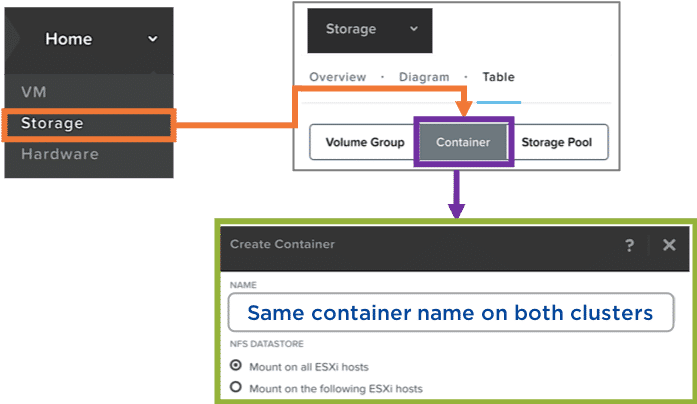
- On the Primary Site, create a new Remote Site (Physical Cluster)
- Specify the remote site Cluster VIP, and previously created containers
- Repeat this on the Standby Site, reversing the settings
vSphere Cluster Configuration

- HA + DRS enabled
- Both Active, and Standby containers need to be mounted to their hosts
- VM’s need to be pinned to the nodes in the cluster where the associated container is active
- Host Isolation Response set to “Power off VM”
Affinity Rules
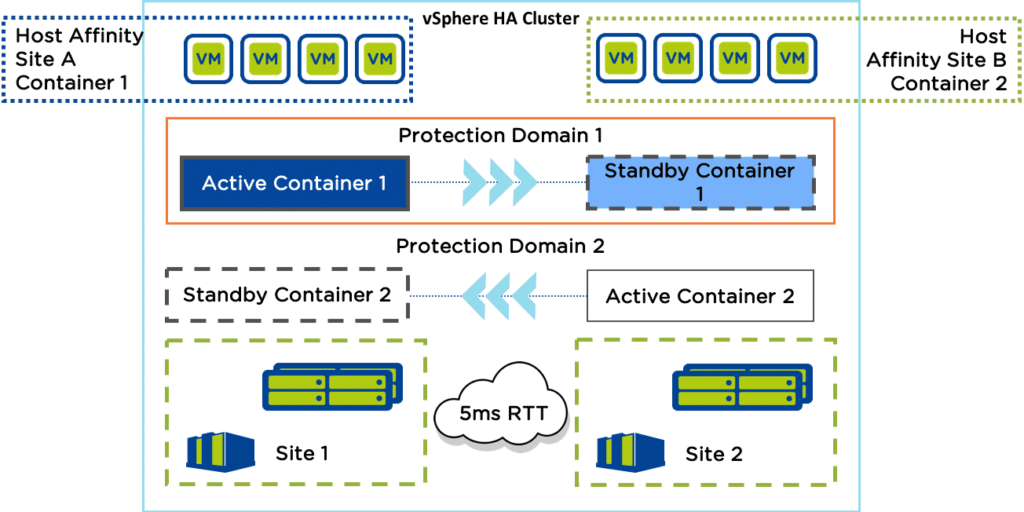
Configure Affinity Rules to pin VM’s in their respective container to the hosts of the Active sites. Example:
- Ruleset 1: Run all Primary Site VM’s on Primary Site Hosts (normal operation)
- Ruleset 2: Run all Primary Site VM’s on Secondary Site Hosts (during failover)

Admission Control

- Set to “Percentage of cluster resources reserved as failover space capacity” to 50% or less (33% default)
- If resource violation is an issue, disable Admission Control entirely.
Protection Domain
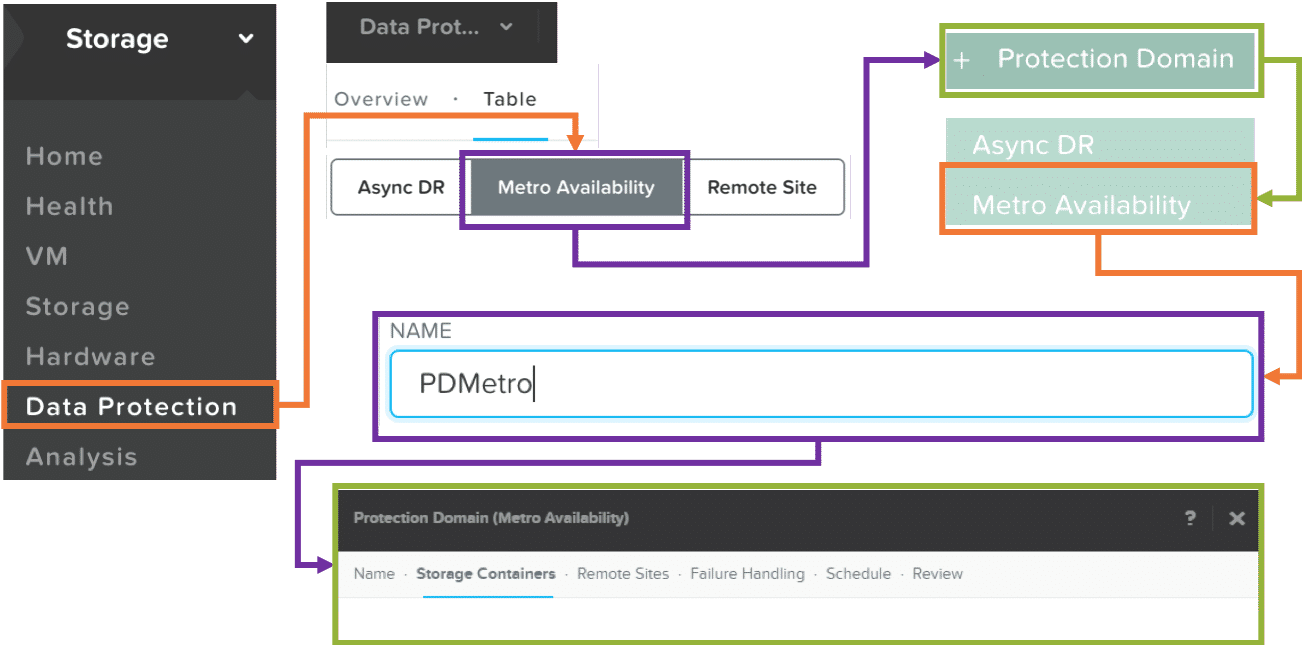
- Create a new Metro Availability Protection Domain
- Validate the remote site is listed in the “Compatible Remote Sites” window
NOTE: Mixing NX and non-NX nodes not supported
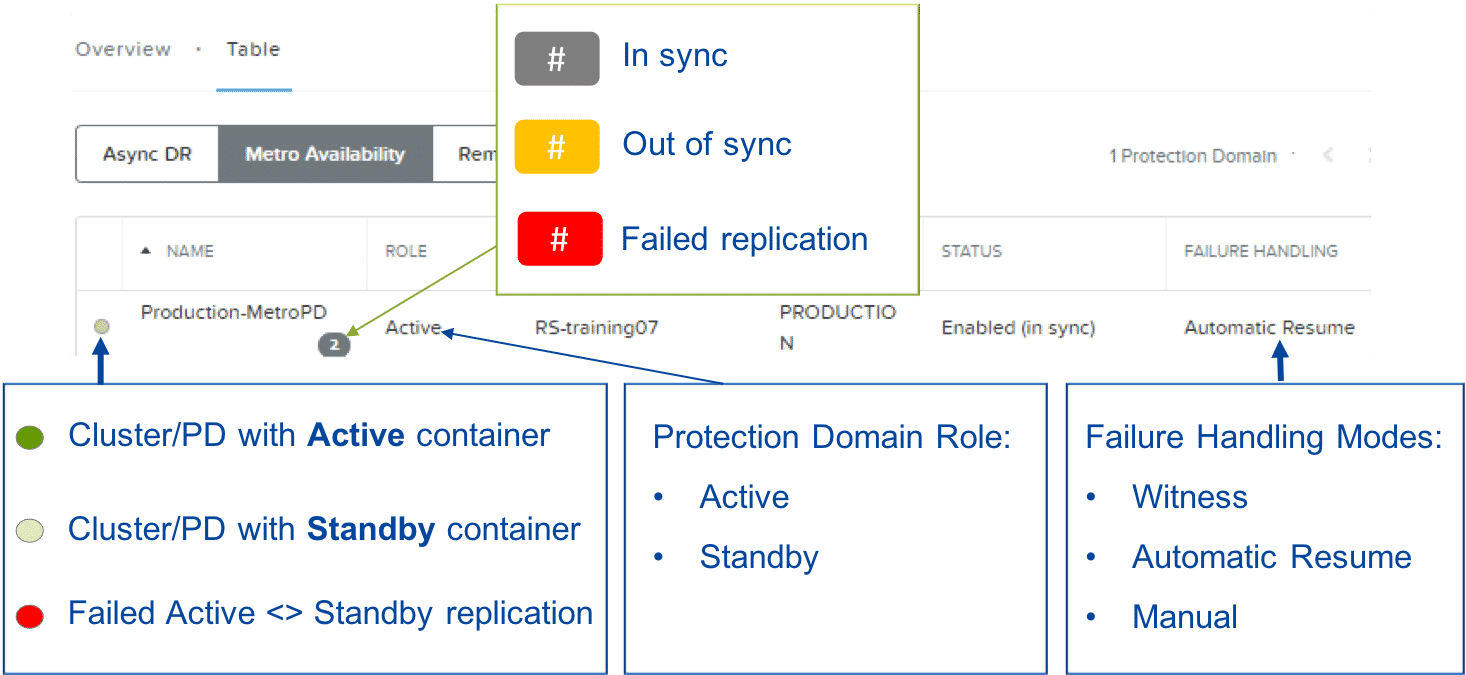
Failure Handling
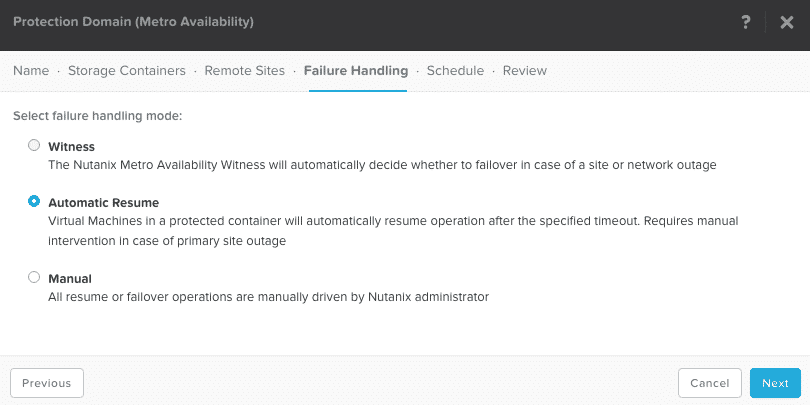
- Witness: (recommended) can automatically distinguish a site failure and decide whether to failover.
- Automatic Resume: VM writes resume automatically (after 10 seconds)
- Manual: VM writes do not resume until a user disables metro availability manually or the problem is resolved
Schedule
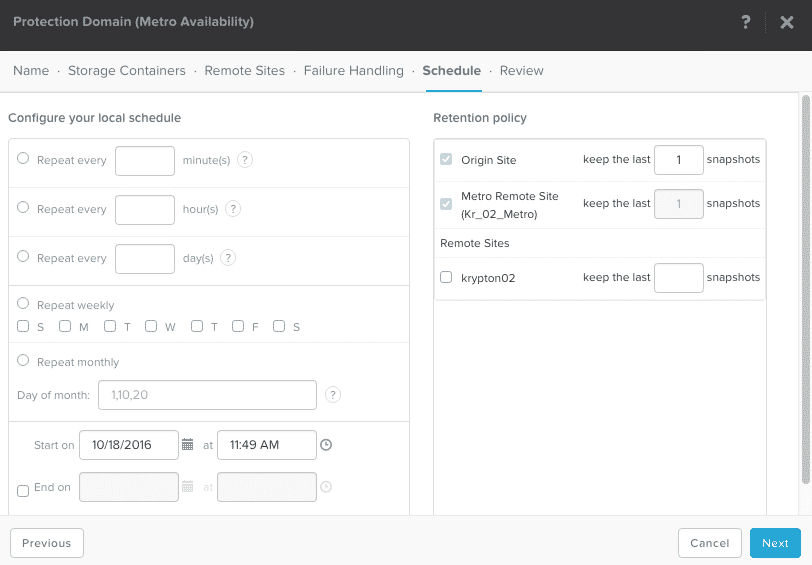
Recommended. By default, hourly snapshots are taken (helps to minimize data replication when metro availability direction is reversed).
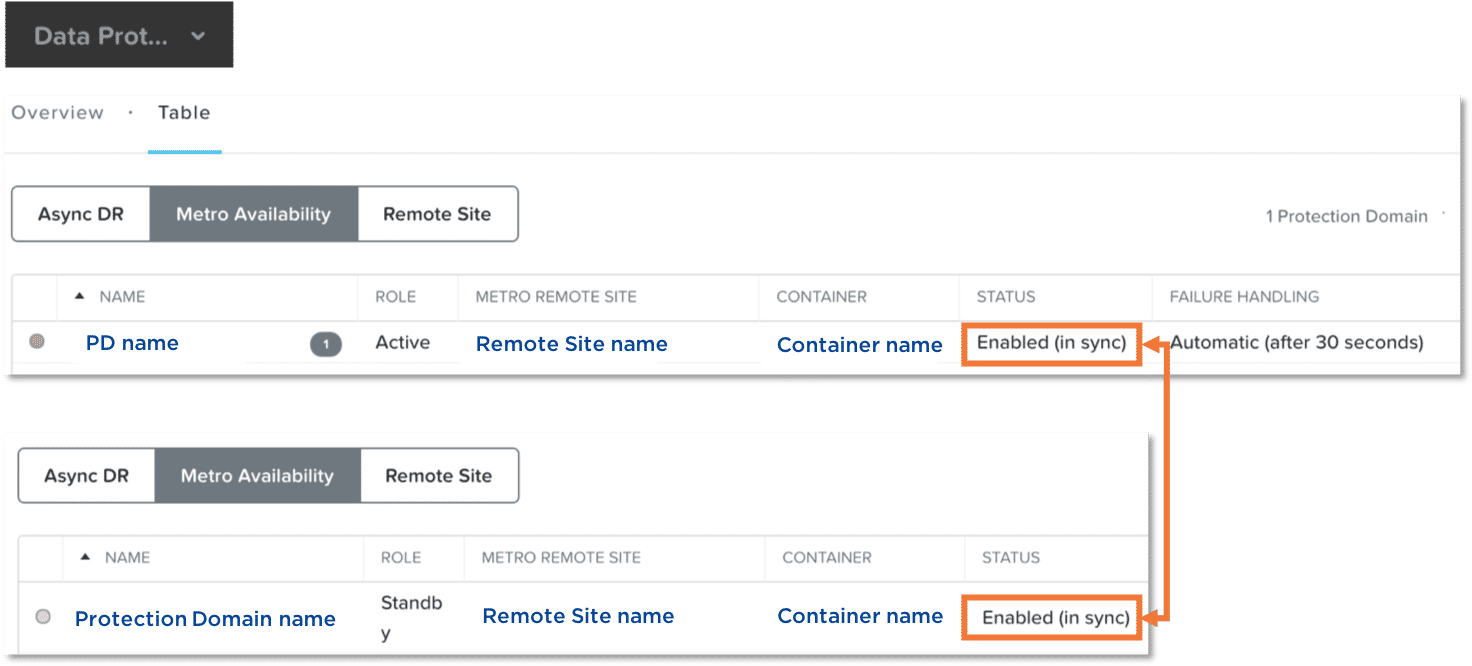
Verify Clusters are in Sync
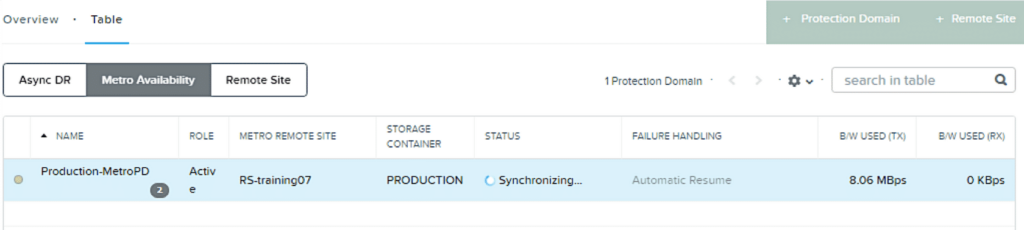
- After initial setup, a full sync will occur. Same for after metro availability is disabled, and then re-enabled.
- Initial snapshot taken on the local cluster, then replicated across DR network to Standby container.
- Deltas are synchronously replicated to Standby container.
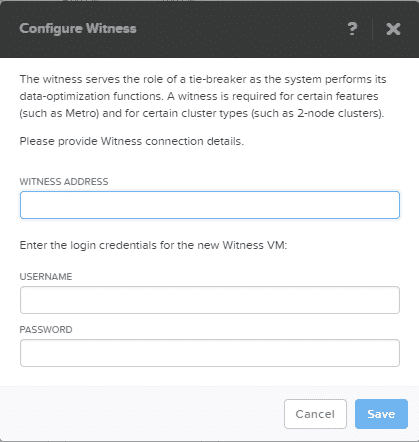
Witness Configuration
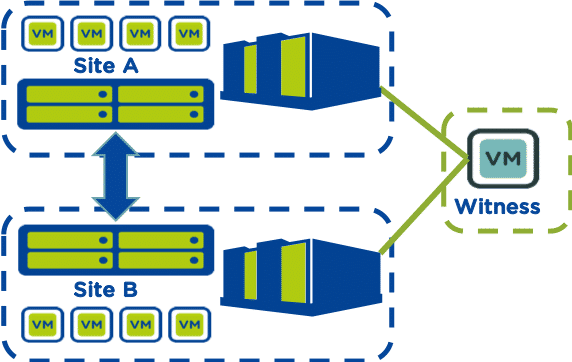
- Scaled down, bare-bones Prism Central VM
- Run outside of MA cluster
- Registers to both Primary/Standby clusters
- Recommended
Configuration
- Deploy the Witness VM using the Witness ova.
- Configure a Static IP Address on the Witness VM.
- Create a Cluster.
- Change the Default Admin Password on the Witness VM.
- Register the Primary Cluster with the Witness VM.
- Register the Secondary Cluster with the Witness VM.
cluster –s <witness_ipaddr> cluster_function_list=Witness_vm create
Convert MA to Witness Mode
Disable Metro Availability and suspend schedules:
ncli> pd metro-avail-disable
ncli> pd suspend-schedules name=<pd_name>
Re-enable Metro Availability:
ncli> pd metro-avail-enable
ncli> pd resume-schedules name=<pd_name>
ncli> pd status
Planned Failover without a Witness
- Failover requires the administrator’s intervention
- Standby container remains standby and not seen by the ESXi hosts
- Promote the standby container.
- Typically, the datastore on the Secondary site will be active, but it is in the read-only state. Unless the Primary container site is unavailable, don’t promote the Secondary site as this can lead to the datastore being readable and writeable on both the sites, which may lead to VM inconsistency or even corruption when a VM is live-migrated from the Primary to the Secondary site.
- The standby container gets mounted on the ESXi hosts
- VMs get restarted on the ESXi hosts
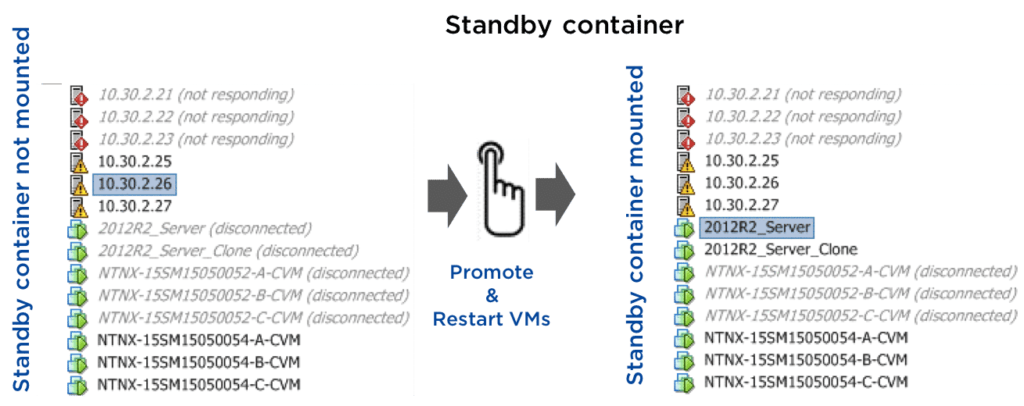
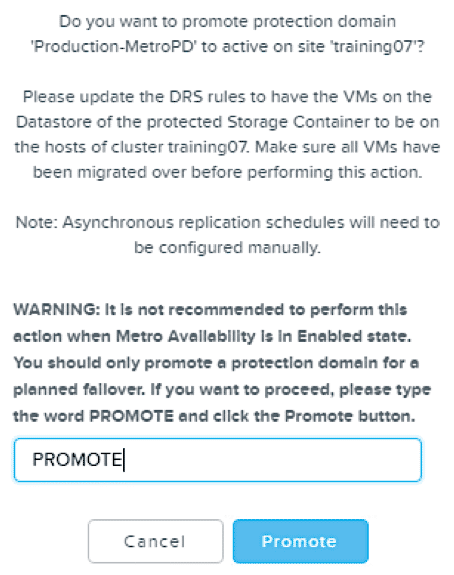
Steps
- Set DRS to manual mode to prevent VMs from being moved back by vMotion to the Primary cluster
- vMotion VMs to the Secondary cluster
- Pin the VMs to the Secondary cluster by VM to host affinity
- Set DRS to “Fully automated”
- Disable MA on the Primary cluster
- Promote the Secondary cluster.
- Standby container becomes the Active container
- Re-enable MA on the Secondary cluster
- MA becomes Enabled (in sync) on the new Primary cluster (which was the remote site before failover).
- MA becomes Enabled (in sync) on the new Secondary cluster (which was the Primary site before failover)
Failure and Failover Scenarios
Primary Site Network Failure without Witness
- In this scenario, both the Primary cluster and the network between the sites fail.
- This cascading failure requires a promote of Metro Availability on the Secondary site.
- After the promote, start the VMs on the Secondary site.
Primary Site & Network Recovery
- Both the Primary site and the network between the sites have recovered.
- The heartbeat between the sites resumes as well.
- At this point, re-enable Metro Availability on the Secondary site.
- With MA enabled again, replication resumes
Unplanned Failover with Witness & Secondary Site Failure
Once the Primary site detects that the Secondary site has a failure observed through loss of the heartbeat between both sites, Metro Availability is automatically disabled without the need for administrator intervention.
Secondary Site Recovery
- At this point, the Secondary site failure has been resolved and the Primary site successfully sends out heartbeats to the Secondary site.
- The administrator can now re-enable MA from the Primary site to resume replication to the Secondary site.
Unplanned Failover with Witness & Network Failure
- In this scenario, the network partition between the Primary and Secondary site has become unavailable. This causes the heartbeat between the two sites to fail. At that point, both the Primary site and the Secondary site attempt to grab MA Witness lock. The Primary site prevails.
- Although MA is automatically disabled on the Primary site by the MA Witness, the container of the Primary site remains active while the container in the Secondary site remains in standby. For any of this to take place, no administrator intervention is needed.
Network Recovery
- Once the network between the DR sites has recovered, heartbeats send by the Primary site to the Secondary site become successful.
- At that point, the administrator can re-enable Metro Availability from the Primary site at which point replication to the Secondary site resumes.
Witness Network Failure
Metro Availability is neither impacted nor disabled.
Witness Network Recovery
- Once network traffic is restored between the sites, the heartbeat between the Primary/Secondary sites and Witness resumes.
- No administrator intervention is needed.
Primary Site with Witness & Complete Network Failure
- In this scenario, a complete network failure occurs. The heartbeat between Primary and Secondary sites is lost. Since the connection between the Primary site and the MA Witness is lost – besides loss of DR (network) connectivity – the Primary site will fail in its attempt to grab the Witness lock.
- The Secondary site also attempts to grab the Witness lock and succeeds.
- With all connectivity lost, the Primary site halts all I/O’s and the VMs will remain in a frozen state.
- At that point, the container on the Secondary site automatically becomes active and the Hypervisor (HA) will failover all protected VMs to the Secondary site.
Primary Site & Complete Network Recovery
- The network of the Primary site is now restored.
- Although the Primary site comes back, it is unable to get the Witness lock and hence won’t make its local container active.
- The heartbeat sent from the Primary site to the Secondary site is, however, successful.
- The administrator can therefore re-enable Metro Availability (MA) from the Secondary site at which point replication resumes.
Secondary Site with Witness & Complete Network Failure
- In this scenario, the Primary site loses its heartbeat with the Secondary site, as well as its connectivity with the MA Witness.
- Whereas the Secondary site is unable to do so, the Primary site grabs the MA Witness lock.
- Without the need for administrator intervention, MA is now automatically disabled on the Primary site, yet all VM traffic continues.
Secondary Site & Complete Network Recovery
The network of the Primary site is now restored. As the Secondary site comes back, the heartbeat sent from the Primary site to the Secondary is successful again. The administrator can now re-enable MA on the Primary site at which point replication resumes.
Complete Network Failure with Witness
- In this scenario, all network traffic has ceased between DR sites and MA Witness.
- With the heartbeat lost between Primary and Secondary sites, both sites attempt to grab Witness lock, but both fail.
- At that point, the Primary site halts all I/O’s and VMs remain in a frozen state.
- The admin is now left with the choice of where
to run the VMs:
- In order to resume the VMs on the Primary site, disable MA on the Primary site
- To force a restart of the VMs on the Secondary site, promote MA on the Secondary site
Complete Network Failure with Witness Recovery
With the networks between DR sites and MA Witness restored, the heartbeat between sites is re-established.
Depending on choice made by the admin to resume VMs (previous slide), the VMs can now, for instance, resume on the Primary site (re-enable MA on the Primary site), or restart on the Secondary site by powering off the VMs on the Primary site and re-enabling MA on the Secondary site.