Explain failover and failback processes
After a protection domain is replicated to at least one remote site, you can carry out a planned migration of the contained entities by failing over the protection domain. You can also trigger failover in the event of a site disaster.
Failover and failback events re-create the VMs and volume groups at the other site, but the volume groups are detached from the iSCSI initiators to which they were attached before the event. After the failover or failback event, you must manually reattach the volume groups to iSCSI initiators and rediscover the iSCSI targets from the VMs.
Migration (Planned) Failover
System maintenance or expansion might dictate moving a protection domain to another site as a planned event.

Migrating a protection domain does the following:
- Creates and replicates a snapshot of the protection domain.
- Powers off the VMs on the local site.
- Note: The data protection service waits for 5 minutes for the VM to shutdown. If the VM does not get shutdown within 5 minutes, it is automatically powered off.
- Creates and replicates another snapshot of the protection domain.
- Unregisters all VMs and volume groups and removes their associated files.
- Marks the local site protection domain as inactive.
- Restores all VM and volume group files from the last snapshot and registers them with new UUIDs at the remote site.
- Marks the remote site protection domain as active.
The VMs on the remote site are not powered on automatically. This allows you to resolve any potential network configuration issues, such as IP address conflicts, before powering on the VMs. Additionally, you must manually reattach the volume groups that were affected by the migration or restore operation, perform in-guest iSCSI attachment. If you use the nCLI for attaching volume groups, note that the UUIDs of volume groups change when they are restored at the remote site, and so do their iSCSI target names, which contain the volume group UUID. See Volume Group Configuration.
Disaster (Unplanned) Failover
When a site disaster occurs, do the following to fail over a protection domain to a remote site:
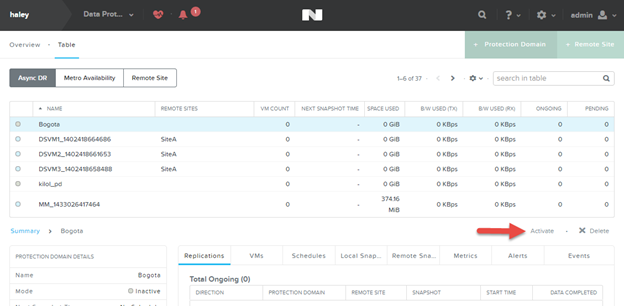
- Log into the web console for the target remote site (see Logging Into the Web Console).
- Go to the Async DR tab of the Data Protection table view (see Data Protection Table View).
- Select the target protection domain and click the Activate button. A window prompt appears; click the Yes button.
This operation does the following:
- Restores all VM and volume group files from the last fully-replicated snapshot.
- The process first detaches the volume groups that are included in the protection domain or attached to the VMs in the protection domain.
- Registers the VMs and volume groups on the recovery site.
- Marks the failover site protection domain as active.
The VMs are not powered on automatically. This allows you to resolve any potential network configuration issues, such as IP address conflicts, before powering on the VMs. Additionally, you must manually reattach the volume groups that were affected by the migration or restore operation, perform in-guest discovery of the volume groups as iSCSI targets, and log in to the targets. If you use the nCLI for attaching volume groups, note that the UUIDs of volume groups change when they are restored at the remote site, and so do their iSCSI target names, which contain the volume group UUID. See Volume Group Configuration.
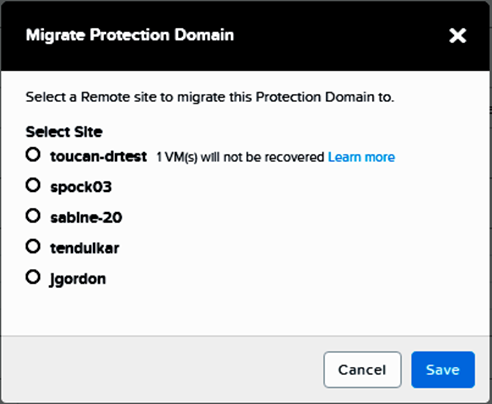
Failing Back a Protection Domain
Perform the following steps to failback a protection domain from remote site to primary site.
- Login to the Web console of the remote site. The site where the protection domain is currently active.
- From the Async DR tab under Data Protection, select the protection domain that you want to failback.
- Click Migrate. The Migrate Protection Domain dialog box appears. Select the site where you want to migrate the protection domain. The VMs that are part of the protection domain, but cannot be recovered on the remote site are also displayed. Click Learn more for additional information.
- When the field entries are correct, click the Save button.
What to do next:
Manually reattach the volume groups that were affected by the migration or restore operation. Note that the UUIDs of volume groups change when they are restored at the remote site, and so do their iSCSI target names, which contain the volume group UUID.
Failing Back a Protection Domain (Unplanned)
If an unplanned failure occurs on the primary site, all the entities are failed over to the remote site. After the primary site gets restored, you can failback the entities to the primary site.
- Log into the vCenter Server of the primary site.
- All the hosts are down.
- Power on all the hosts of the primary site.
- Controller VMs get automatically restarted and the cluster configuration is established again.
- All the protection domains that were active before the disaster occurred gets recreated in an active state. However, you cannot replicate the protection domains to the remote site since the protection domains are still active at the remote site.
- The user VMs get powered on.
- Log on to one of the Controller VMs at the primary
site and deactivate and destroy the VMs by using the following hidden nCLI
command.
- ncli> pd deactivate-and-destroy-vms name=protection_domain_name
- Replace protection_domain_name with the name of the protection domain that you want to deactivate and destroy.
- Caution: Do not use this command for any other workflow. Otherwise, it will delete the VMs and data loss will occur.
- VMs get unregistered at the primary site and the protection domain is no longer active on the primary site. Remove the orphaned VMs from the inventory of the primary site.
- (Optional) If you want to schedule frequent replications, log into the remote site and schedule replication to the primary site.
- Log into the remote site and click Migrate to migrate the protection domain to the primary site. The VMs get unregistered from the secondary site (not removed) and data gets replicated to the primary site, and then the VMs gets registered on the primary site. Protection domain starts replicating from the primary site to the remote site based on the schedule that was originally configured on the primary site.
- Power on the VMs in the correct sequence and configure the IP address again (if required). Additionally, manually reattach any volume groups that were either included in the protection domain or attached to the VMs in the protection domain. You can start using the VMs from the primary site.
- Remove the orphaned VMs from the inventory of the secondary site.